The control plane for your AI stack
Route, track, replay, and eval every LLM call — from one gateway you run yourself. Switch models without fear, and ship AI you can actually trust.
Thanks! We'll be in touch shortly.
- Cost Move checkout to gpt-5-mini save ~$890/mo · replay match 98%
- Reliability Add OpenAI failover on messages Anthropic p95 latency +32% this hour
- Quality Promote claude-sonnet-4.6 +6% on your eval set
Ship AI fast. With visibility and control.
You built observability for everything else in the stack. It's time LLM calls got the same treatment.
The invoice nobody can explain
AI spend is the fastest-growing line item in your P&L, and nobody can say which team, feature, or experiment is driving it. Every call should be attributable.
One provider goes down, everything stops
Your entire product hangs on a single API endpoint you don't control. When it fails at 2am, your customers find out before you do.
Can't test a model switch on real traffic
A new model looks great in the playground. Validating it offline isn't the same as running it live — prove it against real production traffic before you commit.
No CI for AI
You test every code change before it ships. But your LLM outputs — the ones customers actually see — go to production with no scoring, no regression checks, no safety net.
See it in action
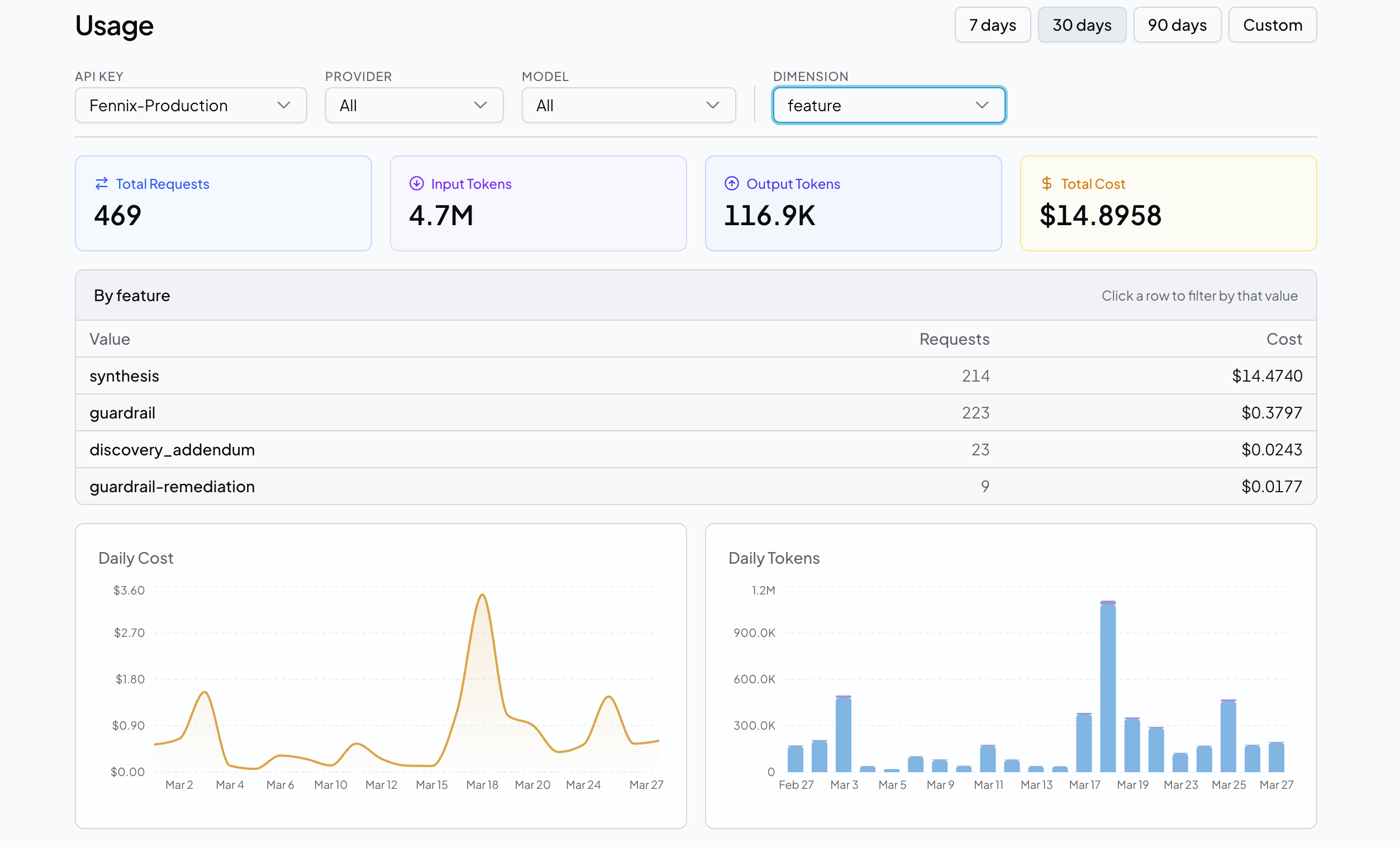
Cost tracking, request logs, and replay results — the dashboard your team actually opens.
No SDK to adopt. No code to rewrite.
Point any client at the gateway and every request comes back with token counts and real dollar costs — in the response headers, or straight from the Python library.
See more examples# Point any SDK at the gateway — costs come back in the response headers
curl http://localhost:7680/v1/chat/completions \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "X-Majordomo-Key: your-key" \
-d '{"model": "gpt-4o", "messages": [{"role": "user", "content": "Hello!"}]}'
# X-Majordomo-Input-Cost: 0.000125
# X-Majordomo-Output-Cost: 0.000250
# X-Majordomo-Total-Cost: 0.000375from majordomo_llm import get_llm_instance
llm = get_llm_instance("openai", "gpt-4o")
response = await llm.get_response("Explain async/await in Python.")
print(f"Cost: ${response.total_cost:.6f}")
print(f"Tokens: {response.input_tokens} in / {response.output_tokens} out")Powering AI at








Everything you need to run LLMs in production
One gateway. Full visibility. Complete control.
Intelligent Routing
Route requests across multiple providers and models from a single endpoint. Automatic failover when a provider goes down. Policy enforcement without changing application code.
Cost & Usage Tracking
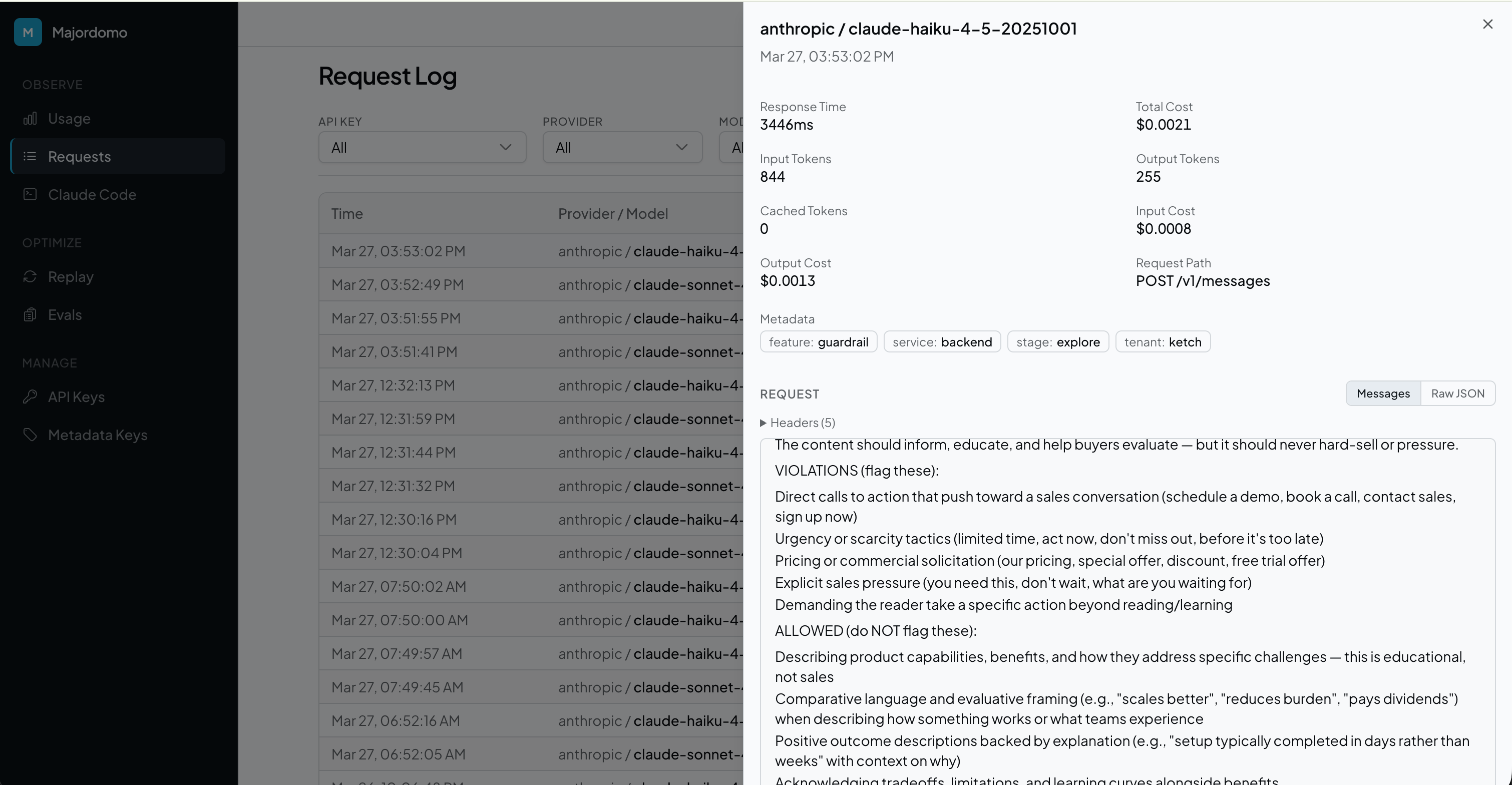
Every request logged with input tokens, output tokens, and cost. Attribute spend by API key, team, feature, or any custom metadata. Daily breakdowns and trend analysis.
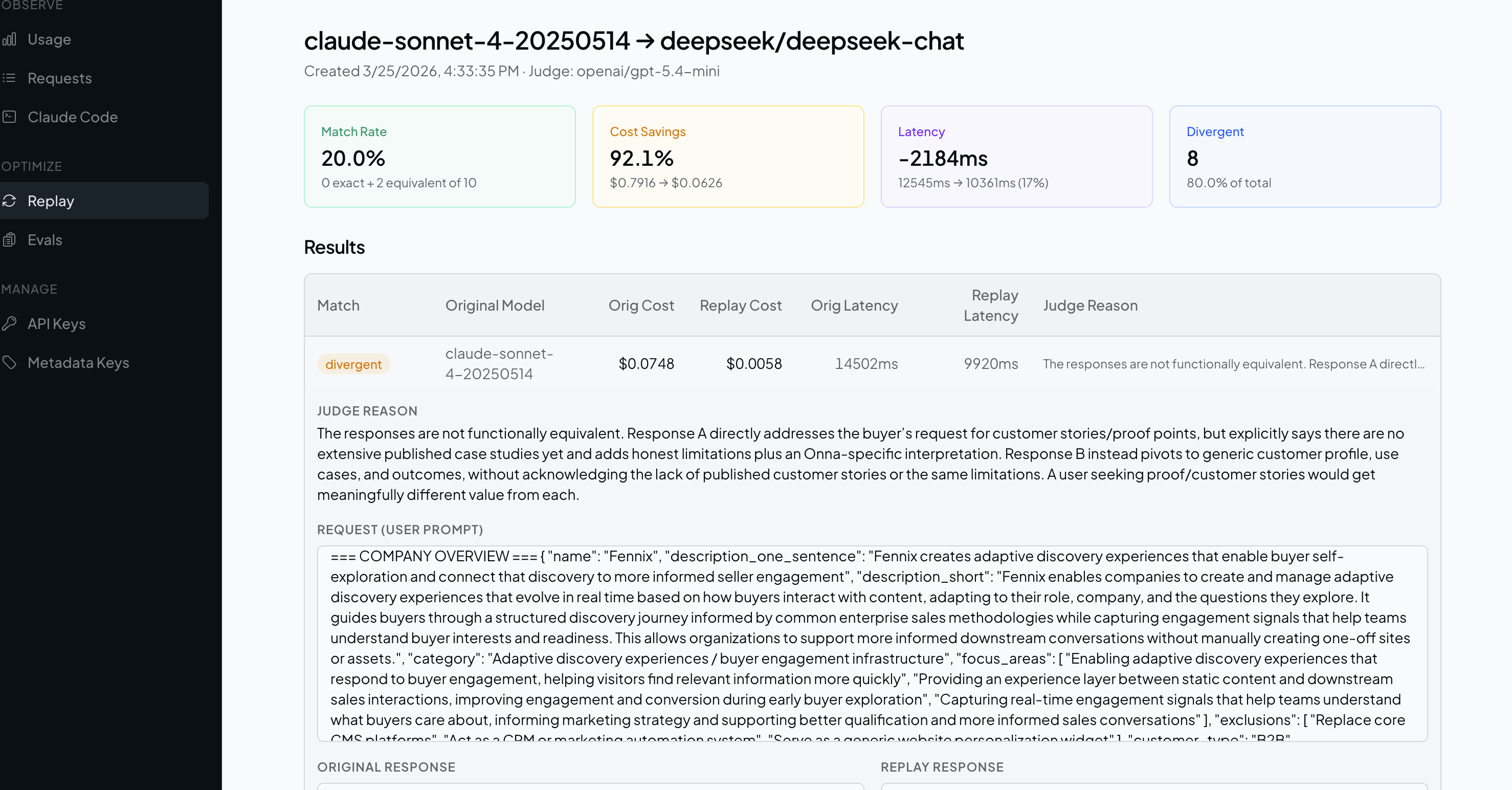
Replay
Take your real production traffic and replay it against a different model. Compare cost, latency, and output quality side by side. Use an LLM judge to score equivalence automatically.
Evals
Build evaluation sets from your logged requests. Define custom scoring criteria. Run evaluations against any model and get aggregate quality scores before you ship.
Experiments
Run live A/B tests across model variants without touching application code. Split traffic by weight, compare cost, latency, and error rates per arm, and use sticky assignment to keep users on a consistent variant.
Your prompts never touch our servers.
Enterprise security reviews ask where your data goes. Majordomo gives you a clean answer: we track cost and usage, we never see content. Not via policies or contracts. Through the right technical architecture.
Gateway in your infrastructure
The proxy runs on your servers, in your VPC, on your cloud account. LLM calls route from your network to your provider. Majordomo is never in that path.
Content to your storage
Request and response bodies are written directly to your S3 or GCS bucket. You own the data, you control access, you set retention. We never receive it.
Metadata only, by design
Majordomo receives tokens, cost, latency, model name, and your custom attributes. The architecture makes it structurally impossible to send us content.
Built for teams that sell to enterprise.
If your customers operate under HIPAA, GDPR, FedRAMP, or strict internal data policies, their security team will scrutinize every vendor in your stack. Observability tools that route prompts through third-party servers are an automatic disqualification.
Majordomo's gateway runs inside your infrastructure. You get full LLM observability — cost attribution, replay, evals — and the data flow diagram that closes the deal.
Up and running in minutes
Connect
Point your SDK or HTTP client at the Majordomo gateway. One line of config — no code changes, no vendor lock-in.
Observe
Every request is logged with tokens, cost, latency, and your custom metadata. See exactly where your AI budget is going.
Test offline
Replay production traffic against a different model. Compare cost, latency, and output quality using an LLM judge before you touch production.
Validate live
Run a production A/B experiment. Split real traffic across model variants, monitor per-arm metrics in real time, and ship the winner with confidence.
Built on open source. Always.
The Majordomo Gateway and client libraries are open source and free forever. Self-host the entire stack, or let us run it for you with Majordomo Cloud.
# Install the gateway
docker pull ghcr.io/superset-studio/majordomo-steward
# Install the Python client
pip install majordomo-llm
Ready to take control of your AI stack?
Get early access to Majordomo Cloud. Start routing, tracking, and optimizing your LLM calls in minutes.
Thanks! We'll be in touch shortly.